VS2022 MCP扩展插件
本来想搜一下codex的lsp功能,Grok搜出来一个vs-mcp的Visual Studio扩展(不是Vscode!),折腾了一下用上了,这里记录下
1. 安装
vs中扩展-管理扩展, 直接搜索 MCP AI Server,然后安装🔧就行了
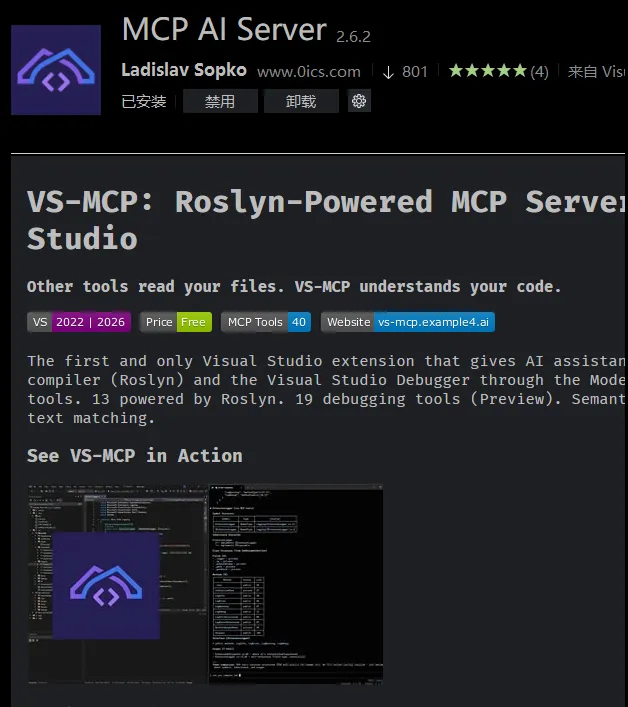
安装后 在工具中会有一个选项,可以启动,配置端口号,开启的工具🔢等;这里应该要手动开启,而且每次都要开启;
日常AI应用随记
日常AI应用实践总结
1. 辅助开发
1.1. 注释生成
- 自研插件 (FineUICoreDesignerPro for VS2022): 在前台文件保存时,利用AI自动读取文件内容,为控件生成注释,方便后台的调用与维护。
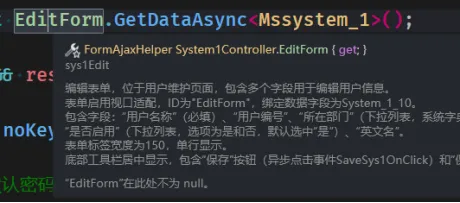
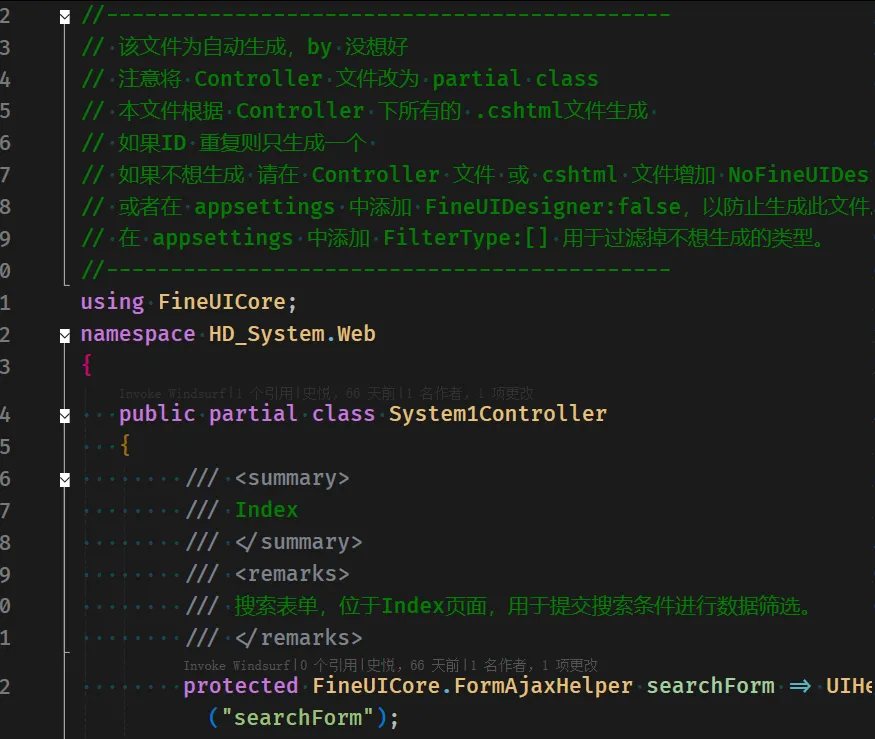
我本来了解Source Generators源生成器但是不知道什么地方用,今天我正好有个需求,从
切面编程用到了Source Generators;这里作为一个典型场景记录
1. 懒
任何代码的封装都是犯懒的结果,今天升级框架的时候要给基础表增加数据变更全局通知的方法,直接通知到前端,这个数据变了刷新一下
本来前端我会这样写 .Sys2DDL()
 就是指定这个下拉控件是一个标准部门控件,应该加载部门数据;这时我可以在
就是指定这个下拉控件是一个标准部门控件,应该加载部门数据;这时我可以在Sys2DDL中绑定数据的同时,注册一个事件,就是等变更的时候重新刷新数据;这样的话就是全局的所有包括Sys2DDL的控件都刷新了不用每个页面自己写;
